



Abstract
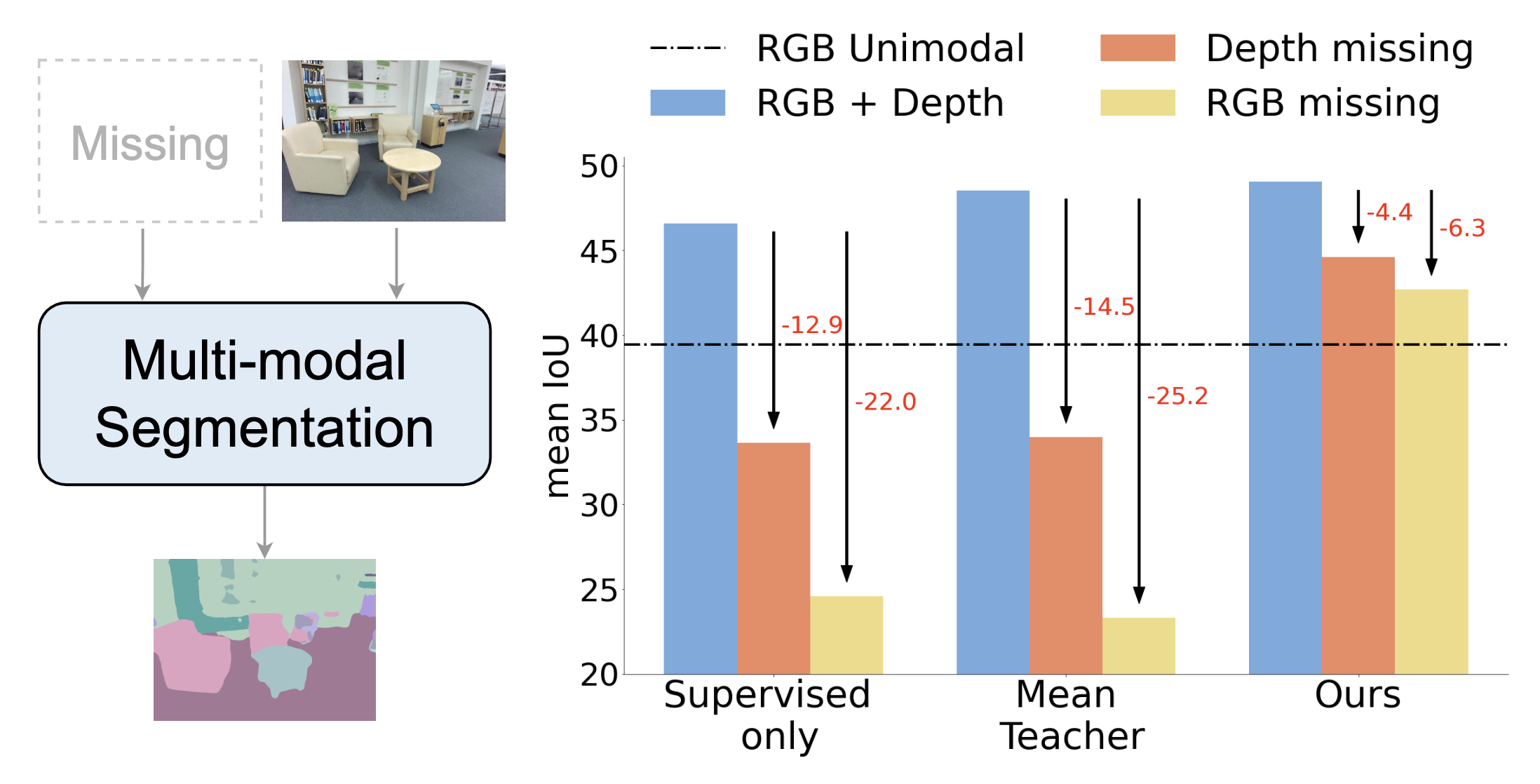
Using multiple spatial modalities has been proven helpful in improving semantic segmentation performance. However, there are several real-world challenges that have yet to be addressed: (a) improving label efficiency and (b) enhancing robustness in realistic scenarios where modalities are missing at the test time. To address these challenges, we first propose a simple yet efficient multi-modal fusion mechanism Linear Fusion, that performs better than the state-of-the-art multi-modal models even with limited supervision. Second, we propose M3L: Multi-modal Teacher for Masked Modaltiy Learning, a semi-supervised framework that not only improves the multi-modal performance but also makes the model robust to the realistic missing modality scenario using unlabeled data. We create the first benchmark for semi-supervised multi-modal semantic segmentation and also report the robustness to missing modalities. Our proposal shows an absolute improvement of up to 10% on robust mIoU above the most competitive baselines.
Video
Paper and Supplementary Material
@InProceedings{Maheshwari_2024_WACV,
author = {Maheshwari, Harsh and Liu, Yen-Cheng and Kira, Zsolt},
title = {Missing Modality Robustness in Semi-Supervised Multi-Modal Semantic Segmentation},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {1020-1030}
}
Hugging face Demo
Qualitative Results

Examples for different multi-modal models
trained with supervised and semi-supervised frameworks.

Examples for visualizing drop in performance when a modality is missing
and robustness to missing modality when trained with the propsed M3L framework.
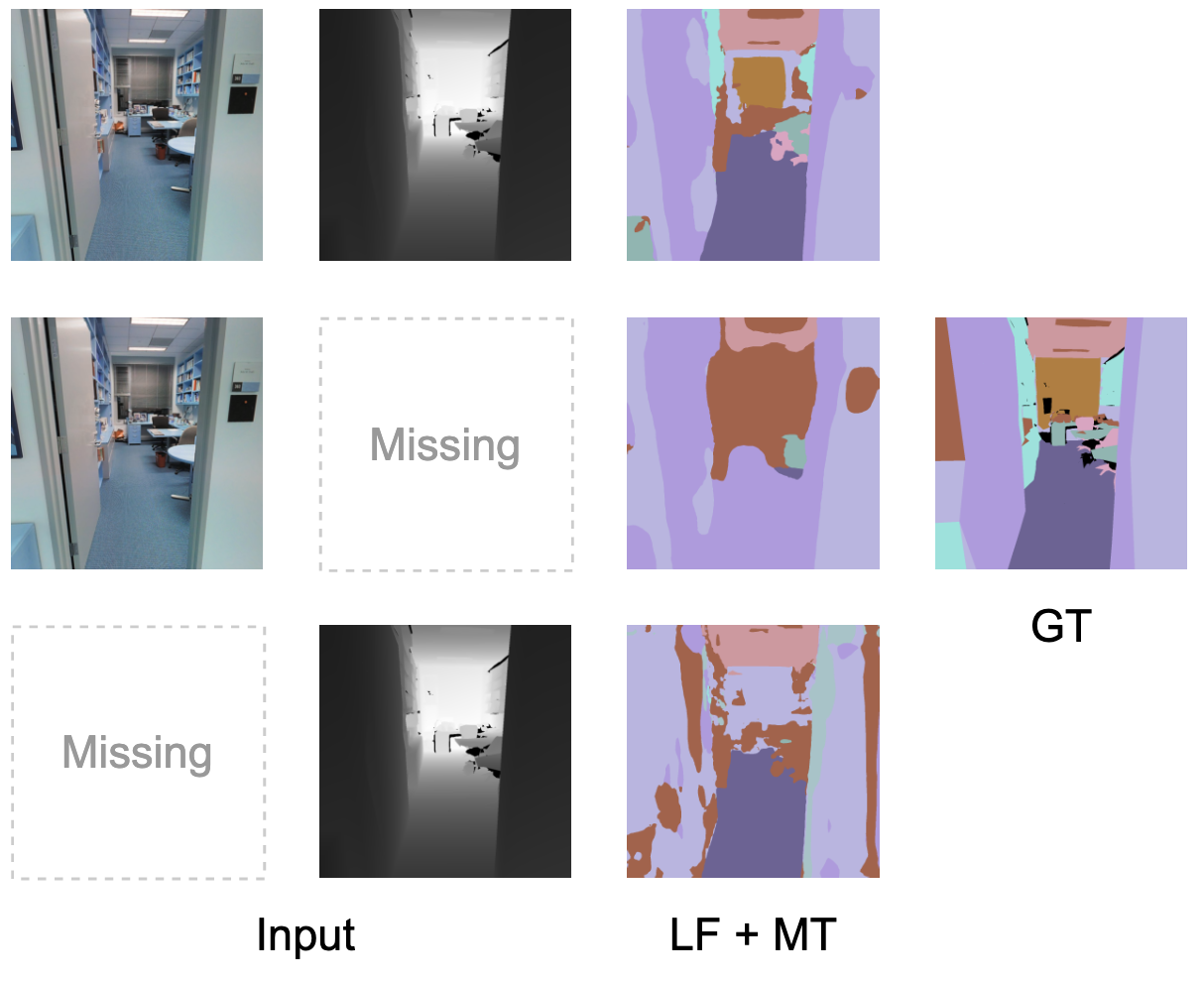
An example to show that when Linear Fusion (LF) is trained with
mean teacher (MT), it is sensitive to the presence of both modalities.

When Linear Fusion is trained with our proposed M3L framework,
the predictions are robust to the missing modalities.